Exploring Data Structure Design Tradeoffs with Various Solutions for Two Sum III

Leetcode #170.
We are tasked with designing a data structure that accepts a stream of integers and checks if it has a pair of integers that sum up to a particular value. To solve this problem, we need to handle tradeoffs between read and write operations: 1. find(value) and 2. add(number). It is not possible to optimize both operations simultaneously without paying for it somewhere else. The interesting part of this problem is not the algorithm itself, but how different representations of the same logical data produce radically different real-world performance characteristics.
I explored these tradeoffs using designs based on hashes, sorted arrays, linked lists and precomputed sums. Each design pushes the cost into either reads, writes, memory usage, or preprocessing. The results explain a lot about how representation shapes performance.
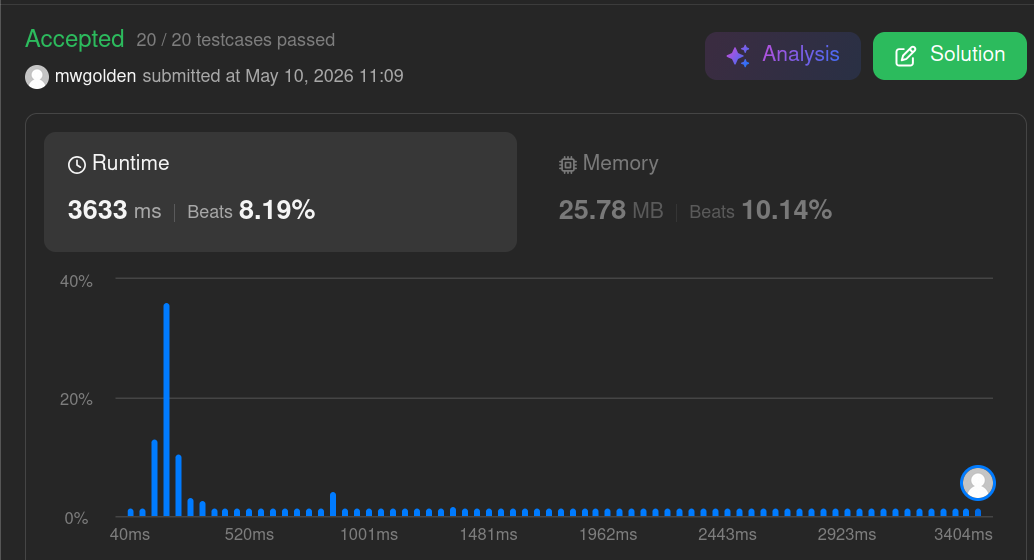
The hash set lookup solution represents data as an unordered, append-only array. This optimizes writes. Structure is applied during find(value) via hashing.
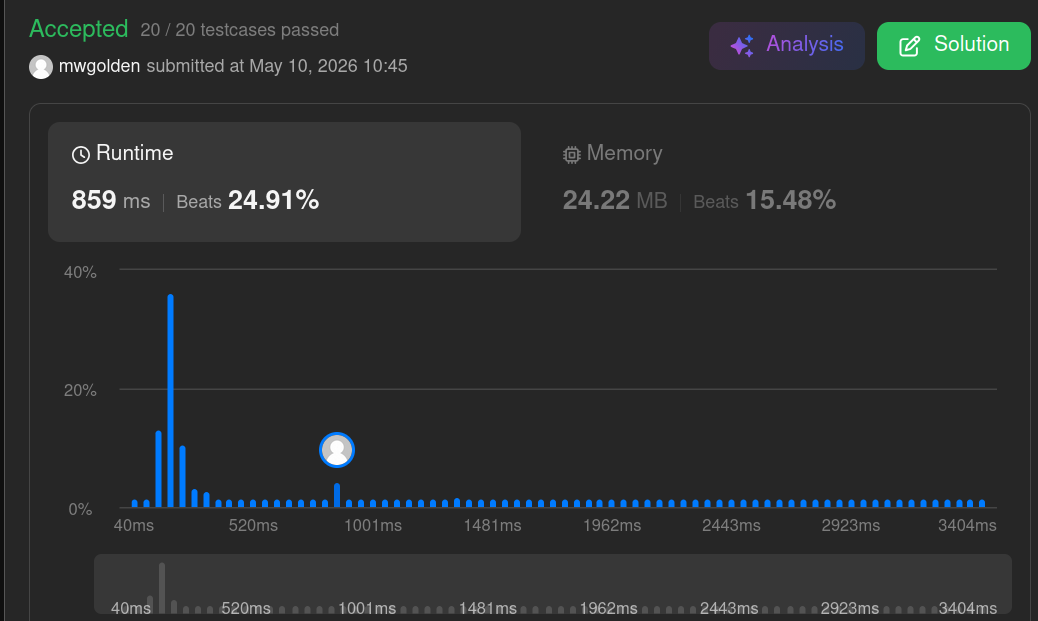
The sorted list + linear insertion solution represents the data as an ordered, contiguous array. This optimizes directional searching at the expense of longer writes.
Similarly, the sorted list + bisect.insort solution represents the data as an ordered, contiguous array. Performance increased because traversal for insertion moved to optimized C code. A good memory layout plus optimized primitives can outperform some better data structures, i.e. the hash set lookup in this case.
The sorted list solutions require arrays to be shifted when data is inserted. Using a doubly linked list avoids the cost of shifting data on write. Insertion at a node is O(1), though finding the insertion point is O(n). Data is represented as a graph of heap-allocated objects. It turns out linked list traversal is extremely expensive in Python. The first iteration failed with TLE.
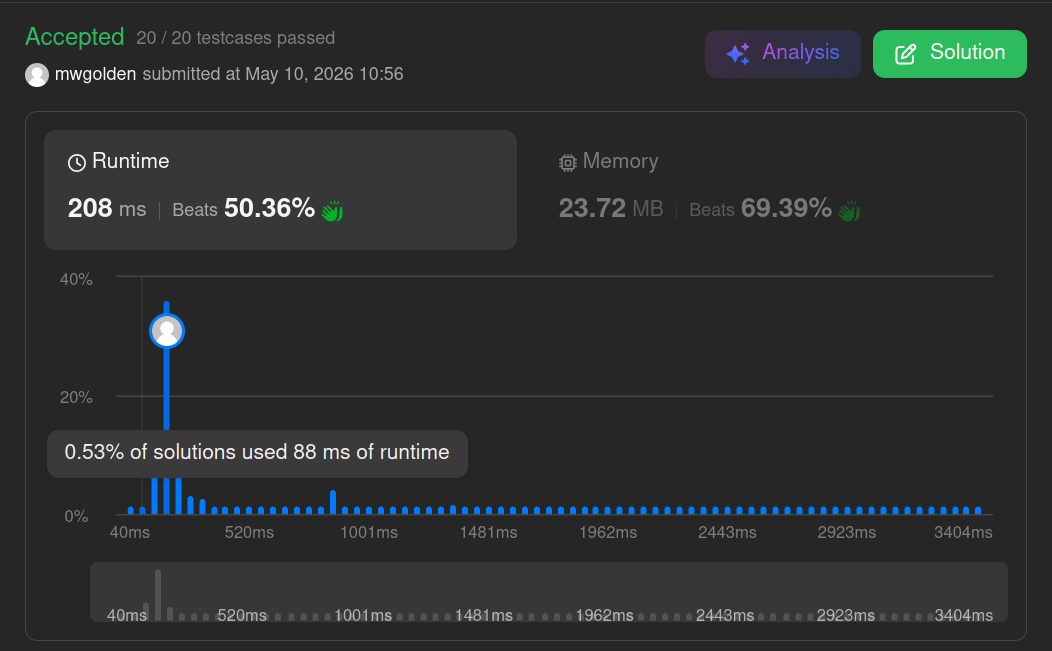
Converting the linked list to a Python list before searching avoids the TLE exception. Sequential traversal over contiguous memory is dramatically cheaper than pointer traversal through Python objects. So, a theoretically unnecessary copy into a contiguous structure can outperform operating directly on the original structure.
Pair-sum computation materializes the query space ahead of time. It is the converse of the hash set lookup solution. Search is an O(1) operation while write is an O(n) operation. In this case, the runtime cost of pre-computing the answers exceeds searching for them in the hash set solution.
Each data representation changed traversal cost, insertion cost, memory layout, and preprocessing requirements. Performance is more than Big-O. Built-in data structure limitations, native C extensions (bisect) and object model overhead can dominate asymptotic complexity.
Hash Set Lookup
The standard solution to this problem uses a hash set lookup. Numbers are stored in an unsorted list. find(value) uses a hash set to detect complements.
class TwoSum:
def __init__(self):
self.number_stream = []
def add(self, number: int) -> None:
self.number_stream.append(number)
def find(self, value: int) -> bool:
visited = set()
for n in self.number_stream:
complement = value - n
if complement in visited:
return True
else:
visited.add(n)
return False
Maintain a Sorted List
What if we maintained a sorted list instead and used the two-pointer technique to find solutions? The sorted list potentially eliminates large portions of the search space without checking every possible pair.
class TwoSum:
def __init__(self):
self.sorted_list = []
def add(self, number: int) -> None:
if not self.sorted_list:
self.sorted_list.append(number)
else:
i = 0
while i < len(self.sorted_list) and self.sorted_list[i] < number:
i += 1
self.sorted_list.insert(i, number)
def find(self, value: int) -> bool:
lo, hi = 0, len(self.sorted_list) - 1
while lo < hi:
n = self.sorted_list[lo] + self.sorted_list[hi]
if n < value:
lo += 1
elif n > value:
hi -= 1
else:
return True
return False
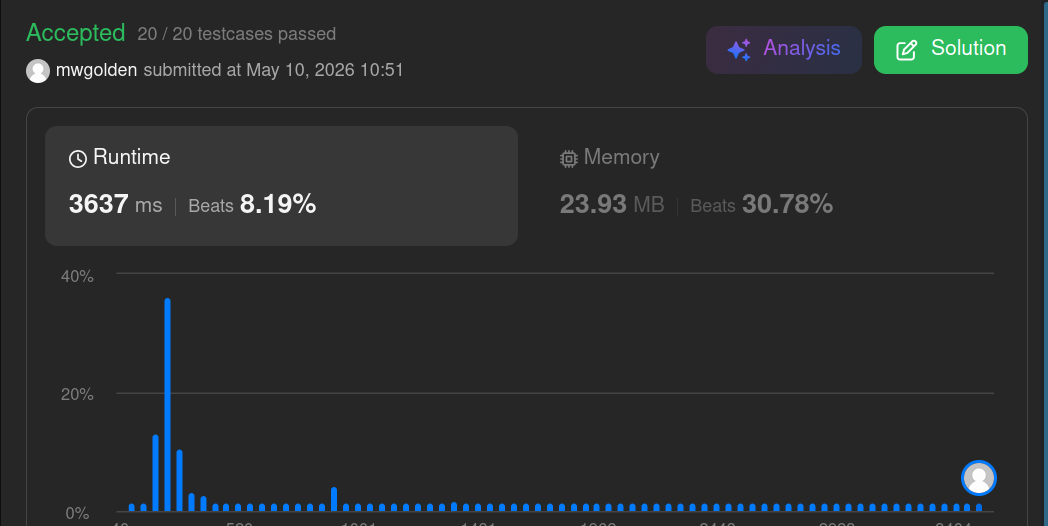
Performance is improved by using Python's bisect module to perform a binary search for the number's insertion point.
import bisect
class TwoSum:
def __init__(self):
self.sorted_list = []
def add(self, number: int) -> None:
bisect.insort(self.sorted_list, number)
def find(self, value: int) -> bool:
lo, hi = 0, len(self.sorted_list) - 1
while lo < hi:
n = self.sorted_list[lo] + self.sorted_list[hi]
if n < value:
lo += 1
elif n > value:
hi -= 1
else:
return True
return False
Linked List vs. Python List
Is there any benefit from avoiding the need to shift elements during an insert? Linked lists theoretically solve this problem because insertion after a node is O(1) and no shifting is required.
This solution hit a TLE exception.
from dataclasses import dataclass
from typing import Optional
class TwoSum:
@dataclass
class Node:
prev: Optional[Node] = None
nxt: Optional[Node] = None
data: int = None
def __init__(self):
self.head: Optional[Node] = None
self.tail: Optional[Node] = None
def add(self, number: int) -> None:
n = self.Node(data=number)
# empty list
if not self.head:
self.head = self.tail = n
return
#insert at head
if number <= self.head.data:
n.nxt = self.head
self.head.prev = n
self.head = n
return
#insert at tail
if number >= self.tail.data:
self.tail.nxt = n
n.prev = self.tail
self.tail = n
return
# insert in middle
curr = self.head
while curr and curr.data < number:
curr = curr.nxt
prev_node = curr.prev
prev_node.nxt = n
n.prev = prev_node
n.nxt = curr
curr.prev = n
def find(self, value: int) -> bool:
if not self.head or self.head == self.tail:
return False
lo, hi = self.head, self.tail
while lo != hi and lo.prev != hi:
total = lo.data + hi.data
if total == value:
return True
elif total < value:
lo = lo.nxt
else:
hi = hi.prev
return False
The two pointer search is optimized by converting the linked list to a normal Python list before searching. This avoids the TLE exception.
def to_list(self) -> list[int]:
nums = []
curr = self.head
while curr:
nums.append(curr.data)
curr = curr.nxt
return nums
def find(self, value: int) -> bool:
numbers = self.to_list()
lo, hi = 0, len(numbers) - 1
while lo < hi:
total = numbers[lo] + numbers[hi]
if total == value:
return True
elif total < value:
lo += 1
else:
hi -= 1
return False
Pair-sum Precomputations
We can shift all work from find() to add() and pay upfront for O(1) queries. But, quadratic memory growth outweighs the theoretical query advantage. N numbers are stored in memory using the hash-set approach, so memory usage is O(n). With pair-sum precomputation, if there are n numbers, then there are n(n-1)/2 possible pairs. Memory is O(n^2).
class TwoSum:
def __init__(self):
self.nums = []
self.sums = set()
def add(self, number: int) -> None:
for n in self.nums:
self.sums.add(n + number)
self.nums.append(number)
def find(self, value: int) -> bool:
return value in self.sums